

Pandas Series object and methods

Hi and Welcome
This is the first of a series of post on the pandas library in python. Pandas is built on NumPy ndarray and matplotlib. It is the fundamental library in python for data analysis, prepossessing, e.t.c. It is rich in methods used for data munging. You can see it as a database whose primary purpose is not for storing data, but easily manipulate and query data, which are features of every database management system.
There are two main objects in pandas, they are pandas Series and DataFrame. This post is primarily on the pandas series , however the methods and operations discussed here also applies to the pandas DataFrame.
Prerequisite: This posts assume that you have knowledge in the NumPy package. If you need a refresher, you can go through my Numpy series of posts.
Enough! Let's get down to business.
In this post, we shall be covering the following
- Pandas Series
- Different methods to create a pandas Series
- Changing the default index
- Pandas Series Operations
- Pandas series Methods
Pandas Series
A pandas series is a one dimensional array. It is a step up from the NumPy array, based on how it is organized. Pandas series are more like columns of an excel sheet.
Just like NumPy array, Pandas series can be created from python list , tuple or dictionary. Let's see how this is done. First , we need to import pandas, with an alias of pd , then create a pandas series.
1 import pandas as pd # imports the pandas package, with an alias of pd
Next , we create a pandas series from a list of ages of individuals. The Series() constructor is used for this purpose. The list is ages=[23,54,23,67,12]. The implementation is as shown below.
1 import pandas as pd
2 ages1=pd.Series([23,54,23,67,12])
3 print(ages1)
The output is

Notice that unlike NumPy , where the indices are implied, in pandas they get printed alongside.
From tuple
1 import pandas as pd
2 ages2=pd.Series([78, 24, 23, 34, 34])
3 print(ages2)
The output is

From dictionary
Pandas series can also be created from python dictionary. In this case , the keys of the dictionary becomes the index of the series while the values remains the array element or values. Below is a data set for the names of residents of a small neighborhood and the their respective number of children, {"Delzy":15,"Henry":13,"Stanley":7,"Smith":5}, to convert this to a pandas series, we use the same process like the others , as shown below
1 number_of_children=pd.Series({"Delzy":15,"Henry":13,"Stanley":7,"Smith":5})
2 print(number_of_children)
The output is

changing the index
Though, a pandas series comes the index named argument.
2 ages3=pd.Series([90, 23, 78, 23, 56], index=["a1", "a2", "a3", "a4", "a5"])
3 print(ages3)

This can also be done after creating the series
2 ages3=pd.Series([90, 23, 78, 23, 56], index=["a1", "a2", "a3", "a4", "a5"])
3 ages3.index=range(5,10)
4 print(ages3)

Series operations and method
The pandas series is filled a lot of method , which are similar(most are the same) with the pandas DataFrame. Also, the basic mathematical operations can be performed
Arithmetic operations
Let's consider the series s1 and s2 below, then perform the basic operations on them
1 import numpy as np
2 import pandas as pd
3 np.random.seed(5)
4 s1=pd.Series(np.random.randint(2,23,5),index=range(1,6))
5 s2=pd.Series(np.random.randint(0, 4, 4),index=range(1,5))
6 s3=s1+s2 # adds values with the same indices
7 s4=s1-s2
8 s5= s1*s2# multiplies elements with the same indices
9 s6= s1/s2
10 s7=s1**s2# exponentiation, with elements of s2 as the exponents
notice that NumPy is used to generate the element of the series. For the sake of consistency in values for me and you , i decided to use the random.seed(5) method.
1 print(s1)

s1 generates five values , as specified in the randint() method
1 print(s2)

s2 generates four values , as specified in the randint() method
1 print(s3)

In the result , index 5 is NaN. this happened since index 5 in s2 is empty(not available), hence NaN (Not a Number). This behavior propagates for all other operations, as shown below
1 print(s4)

1 print(s5)

1 print(s6)

The inf (infinity) in the output is due to division by 0. Unlike vanilla python that would give an exception , NumPy and pandas takes care of this this, by creating an object for this
1 print(s7)

Notice that all these operations returns a pandas series.
Methods
Aggregate methods
Aggregate methods are methods that returns a single value from a sequence. This includes most mathematical and statistical methods , as shown below.
1 print("sum:",s1.sum()) # returns the sum of all values in the series
2 print("product:",s1.prod()) # Returns the product of all values in the series
3 print("maximum:",s2.max()) # returns the maximum value in the series
4 print("minimum:",s2.min()) # returns the minimum value in the series
5 print("mean:",s1.mean()) # returns the mean of the values in the series
6 print("median:",s1.median()) # returns the median of the values in the series
7 print("standard deviation:",s1.std()) # returns the standard deviation of the values in the series
8 print("variance:",s1.var()) # returns the variance of the values in the series

Other methods
There are so many other methods that exists and are pretty useful.
Majority of the results from the above snippet of code can be gotten with a single method .describe(), which gives the statistics of the series.
1 print(s1.describe())
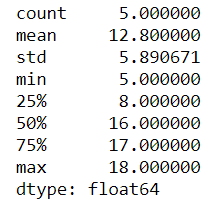
The result is a pandas Series. The % are percentiles.
1 print(s1.cumsum()) # Returns a pandas series , which is the cumulative sum of the elements of s1

1 print(s1.cumprod()) # Returns a pandas series , which is the cumulative product of the elements of s1

There are yet other methods that exists , however we shall discuss them in the next post on the pandas DataFrame object , since the concept remains the same; same goes to indexing.
Conclusion
Harnessing the power of the pandas library is a must for one to be very successful at data manipulation, especially if you want to reduce the time taken in data cleansing. In the next post we shall be considering the pandas DataFrame and some other methods relevant to both DataFrame and Series.
This post is part of a series of blog post on the Pandas library , based on the course Practical Machine Learning Course from The Port Harcourt School of AI (pmlcourse).




